
文字列を検索する
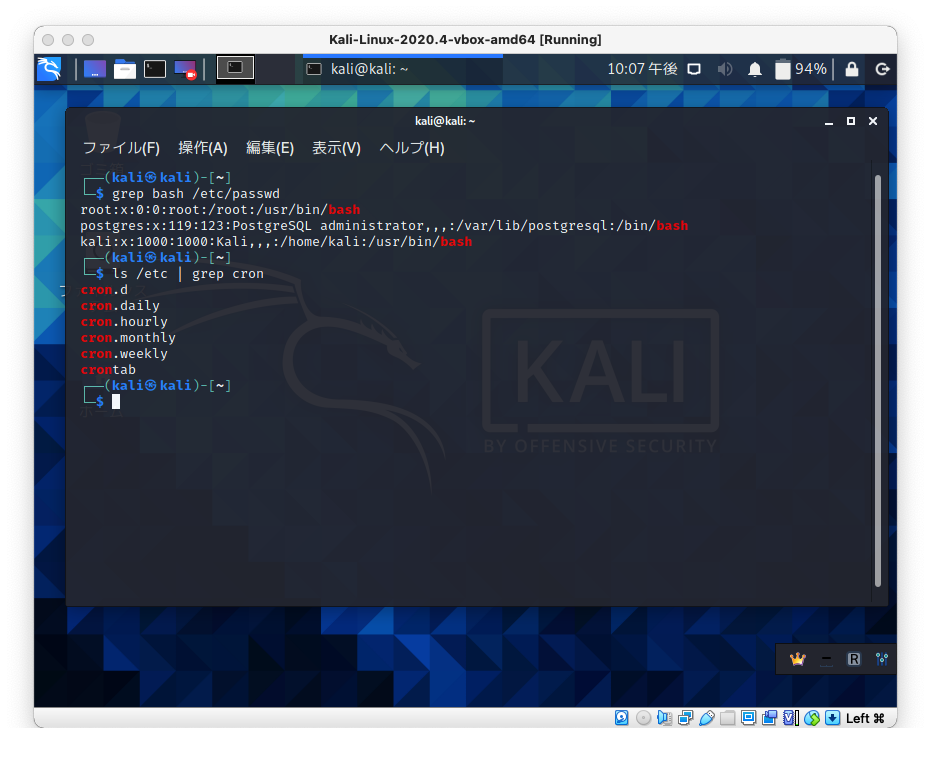
文字列を検索するには、grepコマンドを使います。
grep 検索パターン ファイル名
でOKです。
-nオプションで、マッチした行の行番号を表示できます。
-iオプションで、大文字小文字を区別せずマッチさせます。
-vオプションで、マッチしなかった行を表示できます。
別のコマンドの結果をgrepで検索することもできます。
grepコマンドはマッチした部分だけではなく、マッチした行全体を表示します。
正規表現
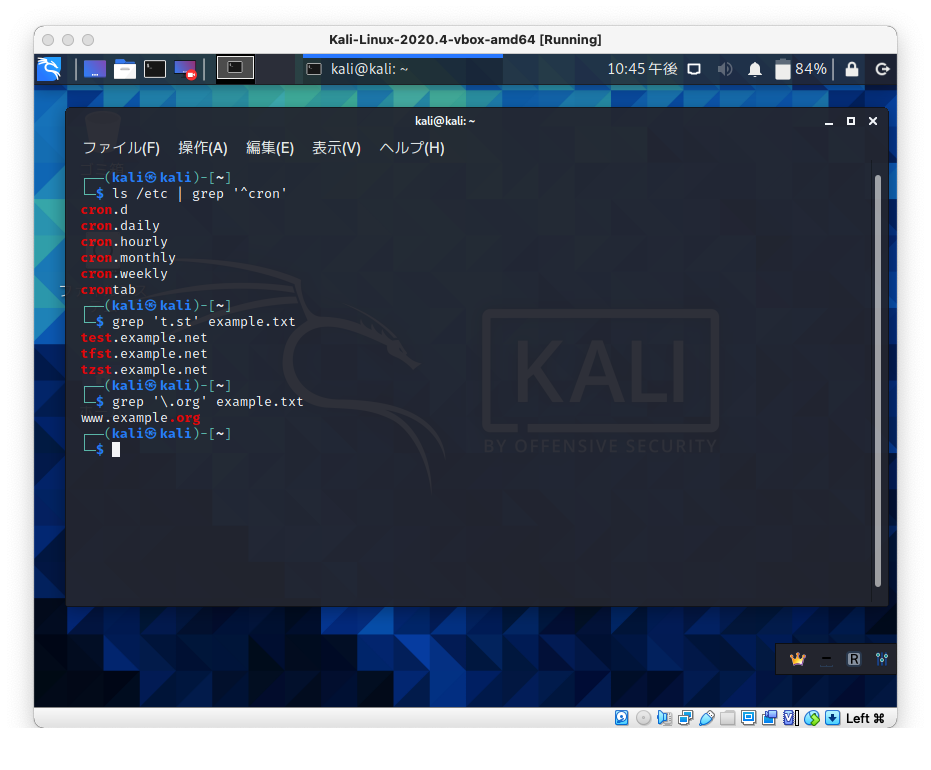
条件に合致する文字列集合を表現するための記法が正規表現です。
正規表現として使用したい記号は、「’」(シングルクオテーション)で囲みましょう。
行の先頭は「^」を使って指定します。
任意の1文字は「.」を使って指定します。
「.」そのもとを検索したいときは、ドットの前に「\」を付けます。
直前に\を置いてメタ文字の意味を打ち消すことを「エスケープする」と言います。
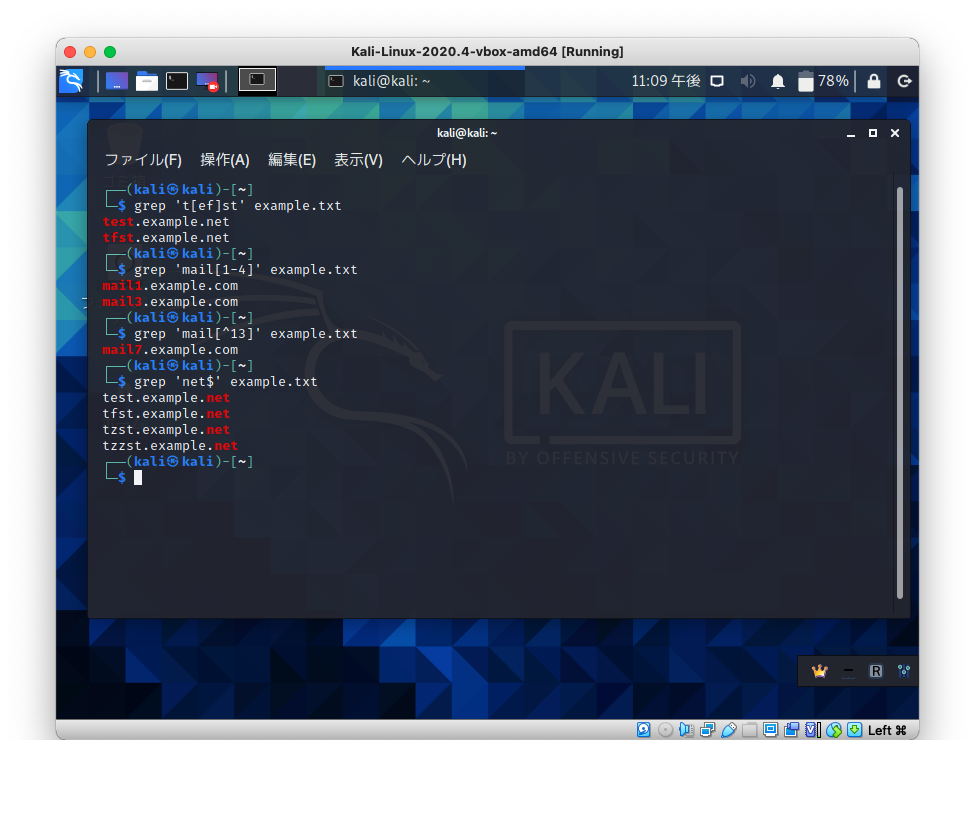
特定の文字は「[ ]」を使って指定します。
[ ]内の文字のいずれかに一致するものという意味です。
-(ハイフン)は文字範囲を意味します。
[a-zA-Z]でアルファベットの大文字小文字すべてという意味になります。
特定の文字以外は「[^ ]」を使って指定します。
行末は「$」を使って指定します。
^$とすると、行頭の直後が行末、すなわち空行にマッチします。
^$と-vオプションを組み合わせると、ファイルから空行だけを取り除いて表示できます。

0回以上の繰り返しは「*」を使って指定します。
ここで0回とは、その直前の文字が存在しなくてもよいという意味です。
拡張正規表現
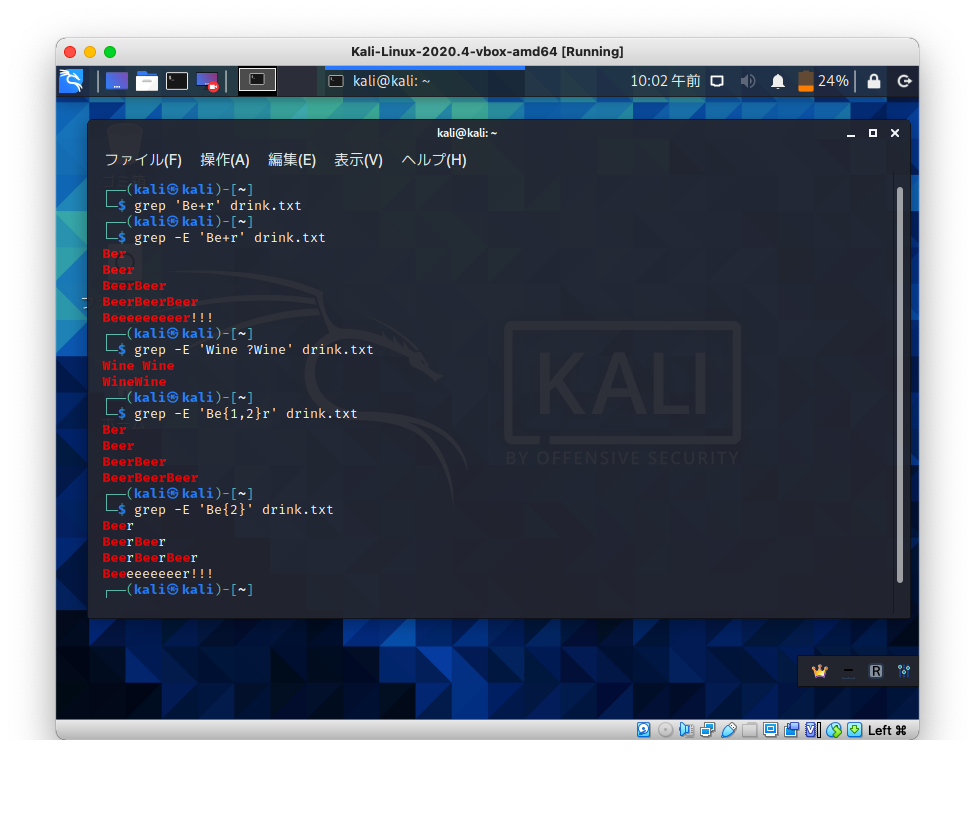
使えるメタ文字を増やした正規表現を「拡張正規表現」と呼びます。
grepコマンドは、オプション無しなら基本正規表現として解釈されます。
-Eオプションを付けると、拡張正規表現として解釈されます。
拡張正規表現「+」は、直前の文字の1回以上の繰り返しを指定します。
「+」は、直前の文字が少なくとも1つは必要であることを意味します。
拡張正規表現「?」は、0回または1回の繰り返しを意味します。
拡張正規表現「{m,n}」は、m回以上n回以下の繰り返しを指定します。
拡張正規表現「{m}」は、ちょうどm回の繰り返しを指定します。
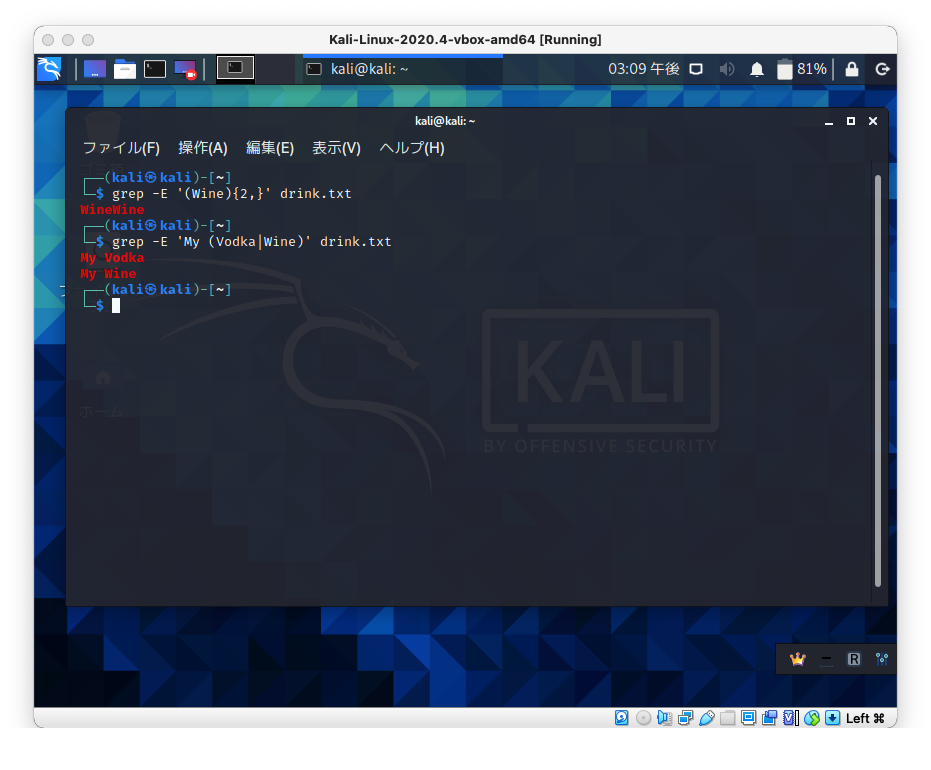
拡張正規表現「{m,}」は、m回以上の繰り返しを指定します。
拡張正規表現「( )」は、単語をグループ化します。
拡張正規表現「|」は、OR条件で複数の単語を指定できます。


コメント